Fotografia: dal greco “scrivere con la luce”. Nulla di più vero, ovviamente: la luce, entrando attraverso l’obiettivo della macchina fotografica, colpisce un pellicola fotosensibile o un sensore (nelle digitali) “impressionandolo”. Nel dettaglio i fototodiodi convertono la luce (il segnle luminoso) in un segnale elettrico, sfruttando le caratteristiche delle giunzioni p-n. Quando un fotone colpisce un fotodiodo, provoca il passaggio di un elettrone in banda di conduzione e la conseguente formazione di una lacuna. Quando nella giunzione p-n arrivano un numero sufficiente di fotoni, vengono formate un numero sufficiente di coppie elettrone-lacuna tali da creare una differenza di potenziale misurabile. Tale differenza di potenziale e’ direttamente legata, come si può intendere, alla quantità di fotoni e quindi all’intensità della luce incidente.

Ci sono due tipi principali di sensori utilizzati nelle fotocamere digitali, chiamati CCD (per il dispositivo ad accoppiamento di carica) e CMOS (per il semiconduttore ad ossido metallico complementare), e, fortunatamente, oggi c’è poco bisogno di capire le differenze tecniche tra di loro, o, anche, quale tipo di sensore risiede nella vostra fotocamera. All’inizio del gioco, i CCD erano i preferiti per l’acquisizione di immagini di alta qualità, mentre i chip CMOS erano l’alternativa “economica” utilizzata per applicazioni meno critiche. Oggi la tecnologia si è evoluta in modo tale che i sensori CMOS hanno superato praticamente tutti i vantaggi che i sensori CCD avevano in precedenza, cosicché il CMOS è diventato il dispositivo dominante per l’acquisizione di immagini, con solo poche ere di camme che utilizzano i CCD. Per chi ha voglia di leggere delle differenze tra i due tipi di sensori, rimando all’articolo CMOS vs CCD: le differenze.
Com’è fatto un sensore fotografico?
Un sensore è un “rettangolo” di silicio sui cui sono impiantati tutta una serie di elementi fotosensibili (i fotodiodi di cui sopra), noti come pixel, dalla dimensione piccolissima (siamo nell’ordine dei micron).
i fotodiodi sono disposti in una serie di righe e colonne. Il numero di righe e colonne determina la risoluzione del sensore. Ad esempio, una fotocamera digitale da 21 megapixel può avere 5.616 colonne di pixel in orizzontale e 3.744 righe in verticale. Questo produce proporzioni 3:2 (o rapporto d’aspetto) che permettono di stampare un’intera immagine su stampe da 15 centimetri e 10 centimetri).
Mentre il rapporto di aspetto 3:2 è più comune sulle reflex digitali, non è assolutamente l’unico utilizzato. Le cosiddette telecamere dei Quattro Terzi di fornitori come Olympus e Panasonic utilizzano un rapporto d’aspetto 4:3; la Olympus E-5, ad esempio, è una telecamera da 12,3 megapixel con un sensore “disposto” in un array di 4032 3024 pixel. Alcune dSLR hanno una modalità di ritaglio “ad alta definizione” per foto fisse che utilizza lo stesso rapporto d’aspetto 16:9 della vostra HDTV.
I sensori delle fotocamere digitali utilizzano lenti microscopiche per focalizzare i fasci di fotoni in entrata sulle aree fotosensibili di ogni singolo pixel/fotosito sulla griglia del fotodiodo del chip. La microlente svolge due funzioni. In primo luogo, essa concentra la luce in entrata sull’area fotosensibile, che costituisce solo una parte della superficie totale del chip (Il resto dell’area, in un sensore CMOS, è dedicata alla circuiteria che elabora ogni pixel dell’immagine singolarmente. In un CCD, l’area sensibile dei singoli fotositi rispetto alle dimensioni complessive del fotosito stesso è più grande). Inoltre, la microlente corregge l’angolo di incidenza relativamente “ripido” dei fotoni in entrata quando l’immagine viene catturata da lenti originariamente progettate per le macchine fotografiche a pellicola. Gli obiettivi progettati specificamente per le fotocamere digitali sono costruiti per focalizzare la luce dai bordi dell’obiettivo sul fotosito; gli obiettivi più vecchi possono dirigere la luce con un angolo così ripido che colpisce i “lati” del “secchio” del fotosito invece dell’area attiva del sensore stesso.
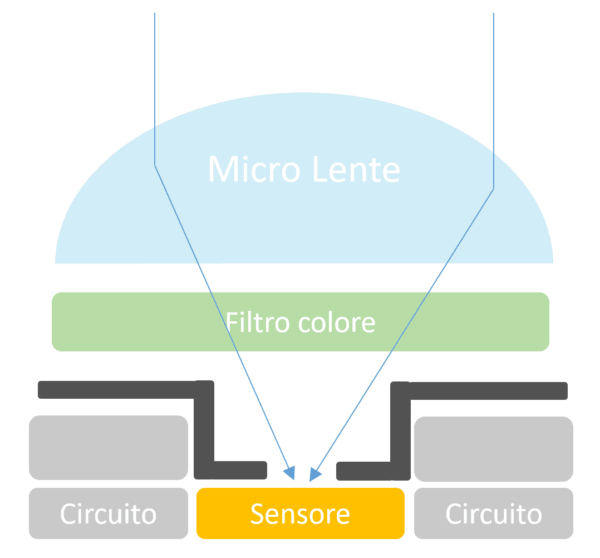
Mentre i fotoni cadono in questo fotosito “secchio”, il secchio si riempie. Se, durante la durata dell’esposizione, il secchio riceve un certo numero di fotoni, chiamato soglia, allora quel pixel registra un’immagine con un valore diverso dal nero puro. Se i pixel sono troppo pochi, quel pixel si registra come nero. Più fotoni vengono afferrati, più chiaro diventa il colore del pixel, fino a raggiungere un certo livello, a quel punto il pixel è considerato bianco (e nessuna quantità di pixel aggiuntivi può renderlo “più bianco”). I valori intermedi producono sfumature di grigio o, a causa dei filtri utilizzati, varie tonalità di rosso, verde e blu.
Se troppi pixel cadono in un particolare secchio, possono in realtà traboccare, proprio come con un vero secchio, e riversarsi nei siti fotografici circostanti, producendo quel bagliore indesiderato noto come fioritura. L’unico modo per evitare il riempimento eccessivo dei fotoni è quello di drenare alcuni dei fotoni in più prima che il fotosito trabocchi, cosa che i sensori CMOS, con circuiti individuali in ogni fotosito, sono in grado di fare.
Naturalmente, ora avete un secchio pieno di fotoni, tutti mescolati insieme in forma analogica come un secchio pieno d’acqua. Quello che si vuole però, in termini informatici, è un secchio pieno di cubetti di ghiaccio, perché i singoli cubetti (valori digitali) sono più facili per un computer all’età dell’uomo rispetto a una massa amorfa di liquido. Il primo passo è quello di convertire i fotoni in qualcosa che può essere gestito elettronicamente, cioè gli elettroni. I valori analogici degli elettroni in ogni fila di un array di sensori vengono convertiti dalla forma analogica (“liquido”) a quella digitale (i “cubetti di ghiaccio”), sia in corrispondenza dei singoli fotositi, sia attraverso circuiti aggiuntivi adiacenti al sensore stesso.
Matrice Bayer
Ogni fotodiodo, come detto in precedenza, genera un segnale elettrico proporzionale alla luce che lo colpisce: leggendo tutti questi segnali elettrici è quindi possibile ricostruire l’immagine finale. In scala di grigi, però. In scala di grigi in quanto un sensore non e’ in grado di leggere il colore: ricordate che le prime televisioni erano, appunto, in “bianco e nero”? Per risolvere questo problema, alla matrice di fotodiodi viene sovrapposta un’identica matrice (in termini di numero e dimensioni degli elementi) di filtri colorati: Rosso (red), verde (green) e blu (bleu). La matrice di filtri segue uno schema ben preciso, inventato da Bryce Bayer e chiamata Bayer Pattern (nella foto in basso). I tre filtri eliminano le componenti di colori differenti da quello del filtro, il che permette al fotodiodo di ricevere una quantità di luce direttamente proporzionale al colore del filtro stesso.
In una matrice Bayer il numero di pixel dotati di filtro verde (G) è doppio rispetto ai pixel rossi (R) o blu (B), nalla proporzione 50% verde, 25% rosso, 25% blu: questo è voluto sia per ridurre il disturbo digitale, sia perché l’occhio umano ha una sensibilità maggiore al verde rispetto al rosso e al blu.
Il processore della fotocamera a questo punto applica un ulteriore algoritmo, chiamato “demosaicing“, attraverso cui estrae da ogni gruppo di 2×2 pixel (2 verdi + 1 rosso + 1 blu) informazioni aggiuntive sul colore, “mescolando” i valori netti dei tre colori primari e interpretando così il colore di quel dato quadrante.
Partendo dai tre segnali (vi dice nulla la sigla RGB?) è possibile, per il processore della macchina fotografica, ricostruire l’immagine finale e quindi permetterci di osservare anche i colori.
Quando la raccolta della luce è terminata (il tempo che definiamo tramite l’otturatore), il valore memorizzato nel fotodiodo (ogni fotodiodo raccoglie il valore di luminanza di un colore, cioè il rapporto tra l’intensità luminosa e l’area della superficie che vi è esposta; si esprime in candele per metro quadro, la sigla è Cd/m2) viene analizzato dal processore che effettua la “demosaicizzazione” (demosaicing): in pratica il processore analizza i pixel in gruppi di 2×2 (2 verdi + 1 rosso + 1 blu) e interpola i valori letti al fine di ottenere il valore equivalente al colore che l’occhio umano percepisce.

Come si può intuire, il sensore è un oggetto molto complesso costituito da più strati e quindi dal costo non indifferente. I sensori vengono “cotti” in serie su dei wafer di silicio: più è grande un sensore, meno sensori sara’ possibile ricavare da un singolo wafer e quindi più alto (e non di poco) sarà il suo costo finale. Tanto per fare un esempio, da un wafer da 8″ è possibile ricavare appena 20 sensori full frame. Se consideriamo che un wafer ha un prezzo che si aggira sui $2000 e che deve essere sottoposto a circa 400/600 lavorazioni (per creare i sensori) prima di essere mandato al taglio, non può stupire il prezzo di una macchina full frame. Tanto per restare in tema di prezzi, le half frame basate su sensori APS-C, costano decisamente meno non perché tecnologicamente inferiori ma per il semplice fatto che sul wafer trovano posto 200 sensori (10 volte le full frame)

Il sensore fotografico: le dimensioni
E’ uno dei fattori determinanti nella qualità di una macchina fotografica ed è, a mio parere, il primo parametro da prendere in considerazione quando si acquista un apparecchio fotografico, soprattutto nell’ambito delle compatte. Troveremo sigle quali APS, FF, 1/1,8″, 4/3″ e cosi’ via: si tratta, in tutti i casi, di valori relativi ai pollici. Ad esempio, 1/1,8″ significa che il sensore ha una diagonale pari a 1/1,8 pollici ovvero 0,5555 pollici. Che tradotto in millimetri significa un sensore dalle dimensioni di circa 7,1×5,3 millimetri (ricordo che 1 pollice e’ pari a 25,4 millimetri).
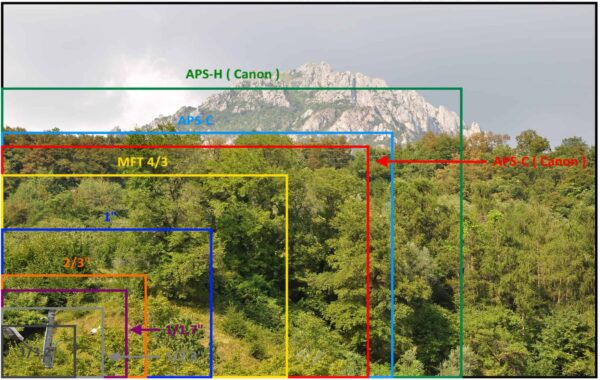
Ecco di seguito una foto che mostra la differenza, in termini di fotografia, delle dimensioni dei sensori a partire da quello full frame la cui dimensione è 36x24mm (la dimensione delle pellicole fotografiche che venivano usate praticamente tutte le apparecchiature fotografiche analogiche).
| Denominazione | Larghezza | Altezza |
| 1/1,8” | 7,2mm | 5,3mm |
| 2/3” | 8,8mm | 6,6mm |
| 4/3” | 18mm | 13,5mm |
| APS-C | Circa 22mm | Circa 15mm |
| Pellicola “piccolo formato” | 36mm | 24mm |
Occhio al “circa” che compare sui sensore APS-C: la dimensione del sensore non e’ sempre la stessa e varia in funzione della “lettera” dopo la sigla APS (Advanced Photo System). L’APS fu lanciato ai tempi della pellicola per una questione di risparmio. Le macchine fotografiche basate su APS usavano delle pellicole piu’ piccole e permettevano di effettuare fotografie in tre dimensioni differenti:
Classico (APS-Classic, APS-C: 23,4×16,7mm): la foto era in un rapporto 2:3.
High Definition (APS-H: 30,2×16,7mm): foto in rapporto 16:9, adatta per la visualizzazione sui televisori di nuova generazione
Panorama (APS-P: 30,2×9,5mm): foto panoramica, particolarmente lunga.
Se questo tipo di tecnologia fu un mezzo fallimento nell’ambito dell’analogico, è il contrario nell’ambito digitale: complice la riduzione di prezzo rispetto alla realizzazione di un sensore a dimensione piena (36x24mm), le macchine fotografiche Reflex half frame implementano dei sensori APS-C anche se ogni produttore ha la sua dimensione. Troveremo sensori 22,7x15mm, 22,2×14,8mm, 23,7×15,6mm, 23,6×15,8mm, e così via. Spesso capiterà anche di trovare, sulle reflex, non il valore in mm del sensore ma il loro rapporto rispetto al full frame: per esempio su Nikon si troverà 1,5 (quindi il sensore Nikon e’ grande 36/1,5:24/1,5), su Canon 1,6.
La dimensione del sensore fotografico. Quando conta?
Tantissimo.
Senza modificare la dimensione dei pixel, dimensione maggiore del sensore significa un maggior numero di pixel (fotodiodi) ospitati sul sensore stesso. Al contrario, se manteniamo costante il numero dei pixel, al crescere del sensore cresce la dimensione dei pixel. Ovviamente ognuno dei due approcci ha vantaggi e svantaggi nonchè differenze di prezzi non indifferenti. Le aziende costantemente fanno “fine tuning” sui sensori, mediando tra le due soluzioni.
Senza entrare troppo nel merito, ricordiamoci che ogni pixel restituisce un segnale elettico. Questo segnale elettrico non è solo composto dalla luce: parte del segnale è costituito da rumore, ovvero da elettroni che si sono eccitati per altri motivi, quali temperatura, pixel vicini, eccetera.
A volte, essendo questo segnale troppo basso, è necessario amplificarlo al fine di ottenere una foto sufficientemente chiara. Questa amplificazione è effettuata dalla macchina fotografica e pilotata dal fotografo che potrà decidere se amplificare per 100, 200, 400 e cosi’ via: il fattore moltiplicativo si chiama, banalmente ISO.
Aumentando l’ISO della macchina, pero’, non si incrementa solo il segnale elettrico relativo all’immagine ma anche il rumore: più è ampio il fattore moltiplicativo (quindi più è alto l’ISO) maggiore sarà il rumore.
Un pixel di dimensioni più grande, a parità di tempo di esposizione e luminosità, cattura più luce di un pixel piu’ piccolo. E quindi genera un segnale elettrico piu’ forte, che necessita di una minore amplificazione. Insomma, pixel piu’ grandi significa foto piu’ luminosa e minore necessità di incrementare l’ISO. Di contro, meno pixel significa meno risoluzione e quindi foto più piccola. Ecco perchè è necessario mediare.
Nelle reflex full frame, essendo il sensore più grande, avremo pixel più grandi di quanto disponibili nelle half frame e soprattutto nelle compatte, dove la “guerra dei megapixel” sta rasentando la buffonata.
Nell’ultima fotografia, riporto la dimensione fisica dei sensori al fine di rendere immediato il parallelo tra i differenti tipi esistenti in commercio (e sulle nostre apparecchiature).







{kind=link}
Comments 3